Turnip Price Prediction
Imagine a market where, every Sunday, a certain trade good (in this case
turnips) becomes available for purchase. Throughout the following week (Monday to Saturday),
the market announces two daily buyback prices (one before 12 AM and another one after)
allowing traders to sell their turnips back at those rates. Naturally, an
 arises:
Based on observed buyback prices, when should one sell to maximize profits?
Answering this question is inherently challenging, and the quality and complexity of
any solution depend heavily on the information available about the specific market.
arises:
Based on observed buyback prices, when should one sell to maximize profits?
Answering this question is inherently challenging, and the quality and complexity of
any solution depend heavily on the information available about the specific market.
In this article, we will develop one such solution for the
turnip market
from the video game Animal Crossing: New Horizons, which, at a basic level, operates
just as described above. Thanks to data-mining conducted by
Ninji, we now understand precisely how buyback prices are determined. Although the process
remains random, this knowledge can be used by traders to gain a significant advantage.
For a comprehensive breakdown, check out
this PDF,
written by
Edricus. Alternatively, you can explore the
raw code
on GitHub. The ready to use tool I created can be found here:
Get rich quick with this simple trick!
High-Level Overview
From the information revealed by the data-mined code, we know that the buyback prices \(X:= (X_1,\ldots,X_{12})\), ordered Monday AM to Saturday PM, always follow one of four distinct patterns: "Decreasing" (DEC), "Small Spike" (SS), "Large Spike" (LS), and "Alternating" (ALT). Furthermore, each pattern can have a multitude of different variations. Most importantly however, there exists only a finite set of possible probability distributions that \(X\) can follow.
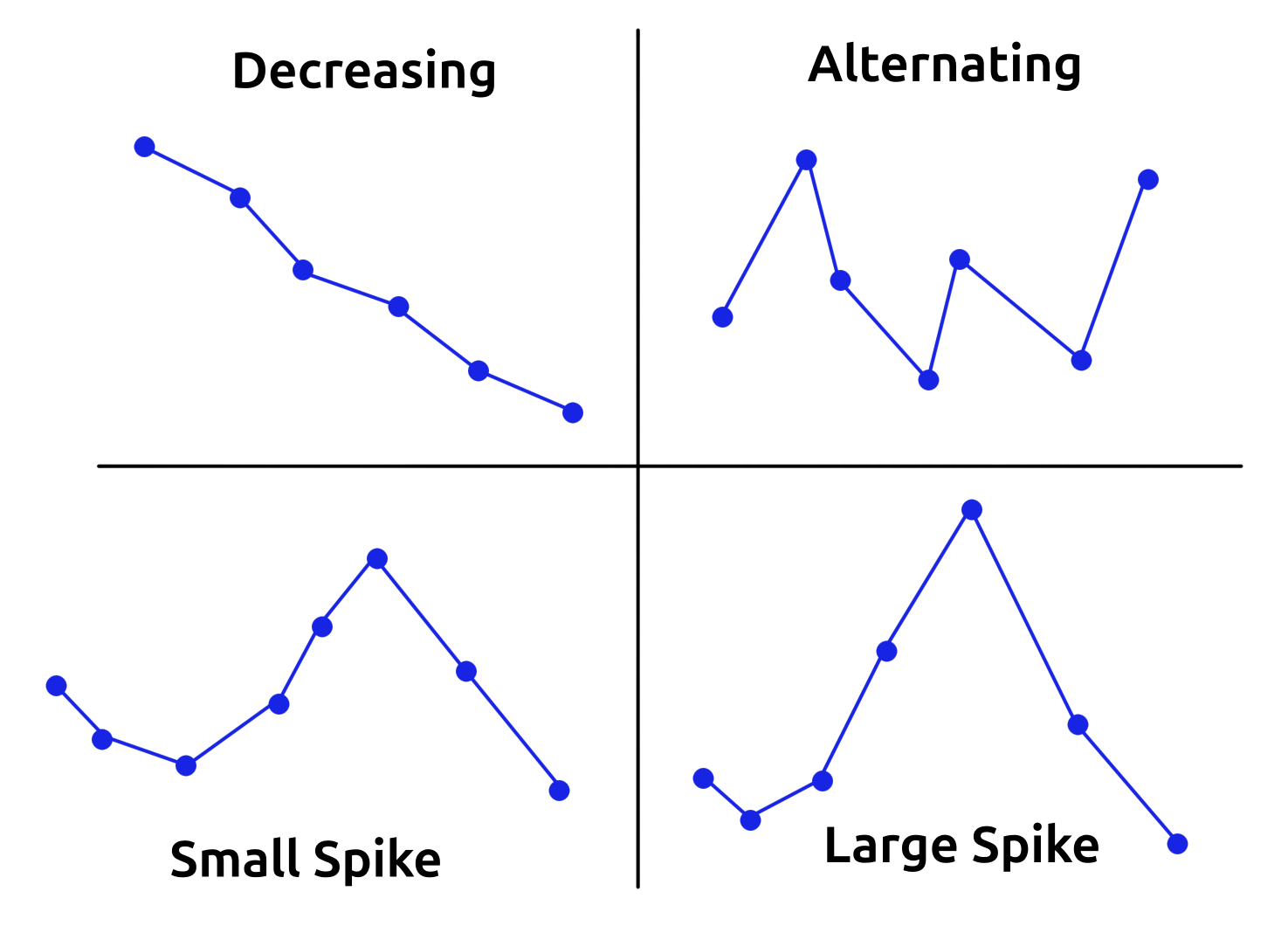
Possible buyback price pattern (placeholder).
Therefore, given observed buyback prices \(X\), we can utilize
Bayes' theorem
together with
the law of total probability
to determine the likelihood that each pattern variation \(V_k\) generated the observed
data.
\[ P(V_k | X) = \frac{P(X|V_k)P(V_k)}{P(X)} = \frac{P(X|V_k)P(V_k)}{\sum_i P(X |
V_i)P(V_i)}\]
These probabilities can then be used to rank all pattern variations, with the
highest-scoring ones providing the desired guidance on when to sell; as the structure
of each pattern indicates clear best-sell windows. That's the whole idea! Pretty easy,
right? However, this time around
 is in the details. In the remainder of this article, we will be deriving formulas and
efficient calculation methods for \(P(X|V_k)\) and \(P(V_k)\), which depending on
\(V_k\) will vary quite a bit in difficulty.
is in the details. In the remainder of this article, we will be deriving formulas and
efficient calculation methods for \(P(X|V_k)\) and \(P(V_k)\), which depending on
\(V_k\) will vary quite a bit in difficulty.
Pattern Transitions
We begin by working on formulas for \(P(V_k)\). To select a pattern variation, the
game first chooses one of the four pattern types \(T_j\). After that it independently
chooses a specific variation \(V_k\) belonging to \(T_j\). Therefore, the probability
of a certain pattern variation being selected actually consists of two terms.
\[ P(V_k) = P(T_j) P(V_k|T_j) \]
The formulas for \(P(V_k|T_j)\) depend heavily on the structure of the pattern type
\(T_j\) and will be derived in the next section. The pattern probabilities \(P(T_j)\)
on the other hand are determined by a predefined
Markov chain
whose state depends on the previous week's pattern \(T^\prime_i\). The corresponding
transition matrix \(\mathbf{P}\) is defined as follows. For a more detailed
introduction to Markov chains, you can check out this other project of mine:
| \(T^\prime_i \to T_j\) | \(\texttt{DEC}\) | \(\texttt{SS}\) | \(\texttt{LS}\) | \(\texttt{ALT}\) |
|---|---|---|---|---|
| \(\texttt{DEC}\) | 0.05 | 0.25 | 0.45 | 0.25 |
| \(\texttt{SS}\) | 0.15 | 0.15 | 0.25 | 0.45 |
| \(\texttt{LS}\) | 0.20 | 0.25 | 0.05 | 0.50 |
| \(\texttt{ALT}\) | 0.15 | 0.35 | 0.30 | 0.20 |
Transition probabilities previous week's pattern \(T^\prime_i\) to this week's one
\(T_j\).
That being said, an immediate issue arises: How do we evaluate \(P(T_j) = P(T^\prime_i \to T_j)\) if \(T_i^\prime\) is unknown? Luckily, a bit of Markov chain theory can help with that. Consider, a row vector \(\pi_n\) representing the probability distribution of choosing any particular state (here the four pattern) at week \(n\). If the Markov chain is irreducible (i.e. every state can be reached from every other state) and aperiodic (i.e. it does not follow a fixed cycle), then a unique limit distribution \(\pi_\infty\) exists, satisfying \[ \pi_\infty \mathbf{P} = \pi_\infty\ \, \text{where}\ \sum_j (\pi_\infty)_j = 1\,. \] By definition, the limit distribution describes the overall probabilities of choosing any particular state and can therefore be used to evaluate \(P(T_j) = (\pi_\infty)_j\) whenever the previous week's pattern \(T^\prime_i\) is unknown. Next, we can easily compute \(\pi_\infty\) by rewriting the above equation as \((\mathbf{P}^T - I)\pi_\infty = 0\) with \(\pi_\infty \gets \pi_\infty^T\) and solving the resulting equation system numerically; for example, using NumPy in Python:
PY
def findStableState(transMat):
dim = transMat.shape[0]
target = transMat.T - np.eye(dim)
mat = np.vstack([target, np.ones(dim)])
vec = np.hstack([np.zeros(dim), 1])
return np.linalg.lstsq(mat, vec)[0]
Python code to find the limit distribution \(\pi_\infty\).
Running this code on our transition matrix \(\mathbf{P}\) yields the missing
transition probabilities if the previous week's pattern is unknown. Finally, one last
detail worth mentioning: If it is the player's first time buying turnips, the game
will always select a "Small Spike" variation, guaranteeing
 .
.
| \(T^\prime_i \to T_j\) | \(\texttt{DEC}\) | \(\texttt{SS}\) | \(\text{LS}\) | \(\texttt{ALT}\) |
|---|---|---|---|---|
| \(\texttt{UN}\) | 0.148 | 0.259 | 0.247 | 0.346 |
Pattern Variations
Each of the four main patterns can be decomposed into a sequence of independent phases, whose lengths are what changes between corresponding variations. In fact, there are only three fundamental phase types: "Decreasing" (\(\texttt{DEC}\)), "Random" (\(\texttt{RAN}\)), and "Custom Spike A" (\(\texttt{CSTA}\)). Everything else is some combination of those. For example, the "Alternating" pattern quite literally just alternates between "Random" and "Decreasing" phases.
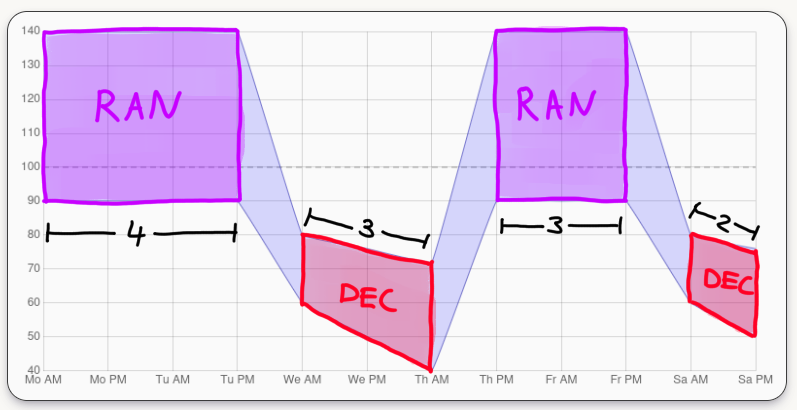
Range of a specific "Alternating" pattern variation
consisting of "Random" and "Decreasing" phases (placeholder).
consisting of "Random" and "Decreasing" phases (placeholder).
The exact procedures used to determine a pattern variation, that is, the lengths of its independent phases, can be inferred from the data-mined code and are described in great detail in the PDF by Edricus. The document also nicely explains when to sell during each pattern, allowing me to refer readers interested in those details to it. Here, I'll simply state the composition of the four main patterns as well as the corresponding formulas for \(P(V_k|T_j)\).
| pattern type \(\,T_j\) | composition variation \(\,V_k\) | \(P(V_k|T_j)\) |
|---|---|---|
| Decreasing | \(\texttt{DEC}\,\) (fundamental) | 1 |
| Small Spike | \(\texttt{DEC}_1, \texttt{RAN}, \texttt{CSTA} , \texttt{DEC}_2\) | \(\frac{1}{\#\texttt{DEC}_1} = \frac{1}{8}\) |
| Large Spike | \(\texttt{DEC}, \texttt{CSTB}, \texttt{RAN}\) | \(\frac{1}{\#\texttt{DEC}} = \frac{1}{7}\) |
| Alternating | \(\texttt{RAN}_1, \texttt{DEC}_1, \texttt{RAN}_2 , \texttt{DEC}_2, \texttt{RAN}_3\) | \(\frac{1}{14}\cdot\frac{1}{7-|\texttt{RAN}_1|}\) |
Pattern type, composition variation, and corresponding probabilities.
Note that "Custom Spike B" (CSTB) simply consists of five independent "Random" phases. Also note that whenever a formula includes a phase name in \(|\cdot|\), it should be replaced by that phase's length. If the phase name is preceded with a \(\#\), it should instead be replaced by the pattern's number of possible lengths for that phase. For example, in a "Small Spike" pattern, only \(\texttt{DEC}_1 \sim \mathcal{U}\{0,...,7\}\) is selected randomly. Every other phase either has a fixed length or is determined by the value of \(\texttt{DEC}_1\). Consequently, we obtain \[ \begin{align} P(V_k|T_j) &= P(\texttt{DEC}_1, \texttt{RAN}, \texttt{CSTA}, \texttt{DEC}_2 \,|\, \texttt{SS})\\[5px] &= \frac{1}{\#\texttt{DEC}_1} = \frac{1}{\#\{0,\ldots,7\}} = \frac{1}{8}\,. \end{align} \]
Basic Code Setup
As discussed, each pattern \(V_k\) can be decomposed into a sequence of independent
phases \(V_k^{(1)},\ldots,V_k^{(r)}\), where \(r\) denotes the sequence length of
\(V_k\). Consequently, both the data \(X \sim V_k\) and the probability\(P(X|V_k)\)
naturally decompose as follows.
\[ \begin{array}{c} \displaystyle X \sim V_k\ \Leftrightarrow
\mathop{\Huge\times}\limits_{i\leq r} X^{(i)} \sim \mathop{\Huge\times}\limits_{i\leq
r} V_k^{(i)} \\[5px] \displaystyle P(X|V_k) = \prod_{i\leq r}
P\big(X^{(i)}\big|V_{k}^{(i)}\big) \end{array} \]
We can mirror this structure in our code architecture by utilizing an abstract parent
class

UML diagram for the PATTERN and PHASE_PATTERN class (TODO).
As always, keep in mind that the UML diagram above highlights only conceptually
important components. If you are interested in the complete implementation, you can
find the full code on
GitHub. As shown in the UML, the non-abstract classes extending
In the next sections we will be focused on first deriving the math behind, and
subsequently implementing, the
JS
// corresponds to (X^(1),...,X^(r)) ~ (V_k^(1),...,V_k^(r))
PHASE_PATTERN.generate = function() {
return this.phases.reduce((prices, phase) =>
prices.concat(phase.generate()), []);
}
// corresponds to P(X|V_k) = P(X^(1)|V_k^(1))*...*P(X^(r)|V_k^(r))
PHASE_PATTERN.evaluate = function(data) {
const copy = [...data]; // copy data before splicing
return this.phases.reduce((prob, phase) =>
prob * phase.evaluate(copy.splice(0, phase.length)), 1);
}
Implementations of generate and evaluate functions for PHASE_PATTERN.
We will skip the
RAN Phase
Earlier we stated that the "Random" phase is not decomposable; however, this is
 . In fact, \(X \sim \texttt{RAN}\) amounts to \(X = (X_1,\ldots,X_n)\), where
\[X_i = \big\lceil b R_i \big\rceil ,\;\; R_i \overset{iid}{\sim}
\mathcal{U}\big[\texttt{min},\,\texttt{max}\big] \,. \]
Therefore, a "Random" phase of length \(n\) can technically be decomposed into \(n\)
independent "Random" phases of length \(1\). In practice however, it is best not to do
so. Next, let \(A_i = \{k_i\}\) correspond to an observation \(k_i \in \mathbb{Z}\),
and let \(A_i = \mathbb{Z}\) denote an unobserved value. By defining
\[lA_i := \begin{cases} \Big[\frac{k_i-1}{b},\,\frac{k_i}{b}\Big], & A_i =
\{k_i\}\\[5px] \big[\texttt{min},\,\texttt{max}\big], & A_i = \mathbb{Z} \end{cases}\]
we can express the probability distribution of \(X\) in terms of the underlying rates
\(R\). Try to get used to this approach now, as the other two phases will be treated
in much the same way. The main complication is that, in those cases, the \(R_i\) are
no longer independent. Clearly we get
\[ P(X=k\,\big|\,\texttt{RAN}) \;\ = \prod_{i \,:\, A_i \neq \mathbb{Z}} P\big(R_i \in
l\{k_i\}\big) \,.\]
To evaluate the inner terms, set \(H := \big[\texttt{min},\,\texttt{max}\big]\), then
integrate the PDF \(f_R \sim \mathcal{U}(H)\) over \(l\{k_i\}\).
\[ P\big(R_i \in l\{k_i\}\big) = \int_{l\{k_i\}} f_R \,d\lambda = \frac{1}{|H|} \int
I_H I_{l\{k_i\}}\,d\lambda = \frac{|H \cap l\{k_i\}|}{|H|} \]
This is a
. In fact, \(X \sim \texttt{RAN}\) amounts to \(X = (X_1,\ldots,X_n)\), where
\[X_i = \big\lceil b R_i \big\rceil ,\;\; R_i \overset{iid}{\sim}
\mathcal{U}\big[\texttt{min},\,\texttt{max}\big] \,. \]
Therefore, a "Random" phase of length \(n\) can technically be decomposed into \(n\)
independent "Random" phases of length \(1\). In practice however, it is best not to do
so. Next, let \(A_i = \{k_i\}\) correspond to an observation \(k_i \in \mathbb{Z}\),
and let \(A_i = \mathbb{Z}\) denote an unobserved value. By defining
\[lA_i := \begin{cases} \Big[\frac{k_i-1}{b},\,\frac{k_i}{b}\Big], & A_i =
\{k_i\}\\[5px] \big[\texttt{min},\,\texttt{max}\big], & A_i = \mathbb{Z} \end{cases}\]
we can express the probability distribution of \(X\) in terms of the underlying rates
\(R\). Try to get used to this approach now, as the other two phases will be treated
in much the same way. The main complication is that, in those cases, the \(R_i\) are
no longer independent. Clearly we get
\[ P(X=k\,\big|\,\texttt{RAN}) \;\ = \prod_{i \,:\, A_i \neq \mathbb{Z}} P\big(R_i \in
l\{k_i\}\big) \,.\]
To evaluate the inner terms, set \(H := \big[\texttt{min},\,\texttt{max}\big]\), then
integrate the PDF \(f_R \sim \mathcal{U}(H)\) over \(l\{k_i\}\).
\[ P\big(R_i \in l\{k_i\}\big) = \int_{l\{k_i\}} f_R \,d\lambda = \frac{1}{|H|} \int
I_H I_{l\{k_i\}}\,d\lambda = \frac{|H \cap l\{k_i\}|}{|H|} \]
This is a
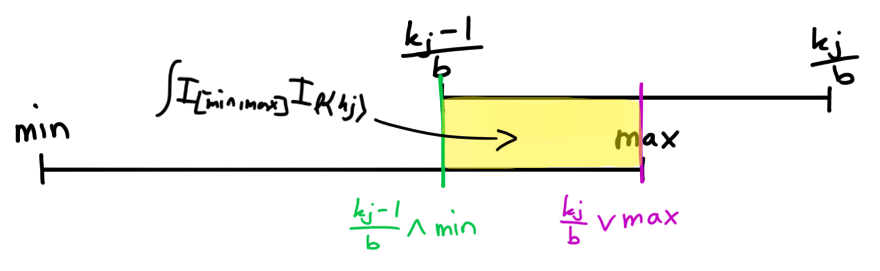
\(H\) and \(l\{k_i\}\) overlapping each other (placeholder).
Similarly the condition \(H \cap l\{k_i\} \neq \emptyset\) can be expressed as conditions to the bounds of the intervals \(H\) and \(l\{k_i\}\). Finally, setting \(a \vee b := \min(a,b)\) and \(a \wedge b := \max(a,b)\), not to be confused with \(\texttt{min}\) and \(\texttt{max}\), we get \[|H \cap l\{k_i\}| = \bigg[\bigg( \frac{k_i}{b} \vee \texttt{max} \bigg) - \bigg( \frac{k_i-1}{b} \wedge \texttt{min} \bigg) \bigg]\, I\bigg\{\frac{k_i}{b} \geq \texttt{min},\, \frac{k_i-1}{b} \leq \texttt{max}\bigg\} \,.\] To calculate \(P(X=k\,|\,\texttt{RAN})\) in code, we just need to directly implement the derived formula, then iterate over all given data points and multiply the results. If we encounter a data point for which the above indicator is zero, we can immediately stop the calculation and simply return zero. Likewise, if a data point is unobserved, we can immediately skip to the next one.
JS
RAN.evaluate = function(data) {
const { base, min, max } = this;
// corresponds to I{k/b >= min, (k-1)/b <= max}
const valid = (point) =>
point / base >= min && (point - 1) / base <= max;
let prob = 1;
for (let point of data) {
// missing datapoint: multiply by 1
// invalid datapoint: return 0
if (!point) continue;
if (!valid(point)) return 0;
// observed datapoint: multiply with P(R_j ∈ l{k_j})
const high = Math.min(point / base, max);
const low = Math.max((point - 1) / base, min);
prob *= (high - low) / (max - min);
}
return prob;
}
Evaluation function of "Random" phase directly implements derived formula.
CSTA Phase
The second phase we will discuss is the "Custom Spike A" phase. As before, let \(H := \big[\texttt{min},\,\texttt{max}\big]\) and define \(Q(m) := \big[ \texttt{min},\,m \big]\). Then \(X \sim \texttt{CSTA}\) means \(X = (X_1,X_2,X_3)\), where \[ \begin{array}{c} X_1 = \big\lceil b R \big\rceil - 1,\;\; X_2 = M,\;\; X_3 = \big\lceil b S \big\rceil - 1\\[2px] M \sim \mathcal{U}(H),\;\; R,S \overset{iid}{\sim} \mathcal{U}(Q(M)) \,. \end{array} \] Notice that the rates \(R,S\) now depend on the rate \(M\). In addition, both \(X_1\) and \(X_3\) now contain an extra "\(-1\)" term. Luckily, this is easy to fix later, allowing us to ignore it for now. With the same sets \(A\) and operator \(l\) as before, consider the following probability \[ \begin{align} & P\big( M \in lA_M, \, (R,S) \in lA_{R \times S} \big)\\[5px] &\qquad\overset{\star_1}{=} \int_{lA_M} f_M \int_{lA_{R \times S}} f_{(R,S)|M} \,d\lambda^2 \ d\lambda\\[5px] &\qquad \overset{\star_2}{=} \int_{lA_M} f_M \bigg( \int_{lA_R} f_{R|M}\,d\lambda \int_{lA_S} f_{S|M}\,d\lambda \bigg)\ d\lambda\\[5px] &\qquad= \frac{1}{|H|} \int_{lA_M \cap H} \rho_R\rho_S\,d\lambda\ \ \ (\star) \end{align} \] where we used the law of total probability at \(\star_1\) and \(lA_{R \times S} = lA_R \times lA_S\) at \(\star_2\). The two inner integrals are essentially identical and evaluate exactly as already seen in the discussion of the \(\texttt{RAN}\) phase above. \[ \rho_R(m) := \int_{lA_R} f_{R|M=m} \,d\lambda = \frac{|Q(m) \cap lA_R|}{|Q(m)|}\ \ \ (\star\star) \] Note \(\rho_R,\rho_S\) analogous. The remaining integral at \((\star)\) can be nicely approximated using a Riemann sum. To this end, let \((x_k)_{j \leq n}\) be a grid on \(lA_M \cap H\) with step size \(\delta_n\). Then it holds \[ \sum_{j \leq n} (\rho_R\rho_S)(x_j)\,\delta_n \overset{n \to \infty}{\longrightarrow} \int_{lA_M \cap H} \rho_R\rho_S\,d\lambda \,.\] Finally, to translate from \(X\) to the underlying rates \(M,R,S\) define \(qx := x + 1\) and replace \(A_R \gets qA_R\) and \(A_S \gets qA_S\). This compensates for the "\(-1\)" offsets in the definitions of \(X_1\) and \(X_3\), yielding \(P(X=k\,|\,\texttt{CSTA}) = P( M \in lA_M, \, (R,S) \in lA_{R \times S})\) as desired. To implement this in code, we begin by defining the indicator appearing in \((\star\star)\), as well as a function for \(\rho_R\) and \(\rho_S\).
JS
// corresponds to I{k/b >= min, (k-1)/b <= m}
const valid = (point, m) =>
point / base >= min && (point - 1) / base <= m;
const rho = (point, m) => {
// [CHECK FIRST] missing datapoint: return 1
// invalid datapoint or bad division: return 0
if (!point) return 1;
if (!valid(point, m) || m == min) return 0;
// observed datapoint: return rho(m)
const high = Math.min(point / base, m);
const low = Math.max((point - 1) / base, min);
return (high - low) / (m - min);
};
Implementation of \(\rho_R,\rho_S\) functions.
Next, we set up the integration by determining the bounds of the integration region
and defining the integrant \(x \mapsto (\rho_R\rho_S)(x)\). Note that the the shifts
\(A_R \gets qA_R\) and \(A_S \gets qA_S\) are implemented by adding \(1\) to the
points
JS
// corresponds to min(k_M/b, max) and max((k_M-1)/b, min)
const high = !!M ? Math.min(M / base, max) : max;
const low = !!M ? Math.max((M - 1) / base, min) : min;
// corresponds to integrand x ⟼ (ρ_Rρ_S)(x)
const fun = (x) => rho(R + 1, x) * rho(S + 1, x);
Integration bounds and integrand code.
Putting everything together, the
JS
CSTA.evaluate = function(data, steps = 50_000) {
const { base, min, max } = this;
const [R, M, S] = data;
// implemented as stated above
const valid, rho, low, high, fun;
// if integration region empty return prob 0
if (!!M && !valid(M, max)) return 0;
const approx = CSTA.integrate(fun, low, high, steps);
return approx / (max - min);
}
Evaluation function of "Custom Spike A" phase utilizing a Riemann sum.
DEC Phase (MC)
Oh boy did I get
We will begin by discussing the MC approach. For that, let \(H_1 := \big[\texttt{init.min},\,\texttt{init.max}\big]\) and \(Q := \big[\texttt{delta.min},\,\texttt{delta.max}\big]\). Then \(X \sim \texttt{DEC}\) is defined as \(X = (X_1,\ldots,X_n)\), where \[ \begin{array}{c} X_i = \big\lceil bR_i \big\rceil, \;\; R_{i+1} = R_i - \Delta_i\\[2px] R_1 \sim \mathcal{U}(H_1), \;\; \Delta_i \overset{iid}{\sim} \mathcal{U}(Q) \,. \end{array} \] We are interested in the probability \(P(R \in lA) = \int_{lA} f_R \,d\lambda^n\) where \(R = (R_1,\ldots,R_n)\) and \(lA := lA_1 \times \cdots \times lA_n\). Since \(R_{i+1}\) depends on \(R_i\) evaluating this integral directly quickly becomes unwieldy. Instead, we will find the probability distribution of \(R\), allowing us to come up with a clever way to approximate \(P(R \in lA)\). To this end, consider \(\Delta := (R_1,\Delta_2,\ldots,\Delta_n)\), whose components are independent, making it easy to find its PDF \[ \begin{align} &f_\Delta(h_1,s_2,\ldots,s_n) = f_1(h_1) \prod_{i \geq 2} f_Q(s_i)\\[5px] &\qquad = \frac{I\{h_1 \in H_1\}}{|H_1|} \prod_{i \geq 2} \frac{I\{s_i \in Q\}}{|Q|}\\[5px] &\qquad = \frac{I\big\{h_1 \in H_1,\, \forall i \geq 2 : s_i \in Q\big\}}{|H_1|\,|Q|} \end{align} \] where \(f_1 \sim \mathcal{U}(H_1)\) and \(f_Q \sim \mathcal{U}(Q)\). Next, we will use the PDF transformation theorem \((\star)\) to derive \(f_R\) from \(f_\Delta\). Consider a linear map \(T : \mathbb{R}^n \to \mathbb{R}^n,\, x \mapsto Tx\) given by the triangular matrix \[ T = \left[ \begin{smallmatrix} 1 \\ 1 & -1 \\ \vdots & \vdots & \ddots \\ 1 & -1 & \cdots & -1 \end{smallmatrix} \right],\ T^{-1} = \left[ \begin{smallmatrix} 1 \\ 1 & -1 \\ & \ddots & \ddots \\ & & 1 & -1\end{smallmatrix} \right]. \] It holds \(T\Delta = R\) as desired and \(\det T = (-1)^{n-1} \neq 0\), allowing us to apply the theorem. For \(h \in \mathbb{R}^n\) we obtain \(f_R\), which is guaranteed to be a PDF (this will be important in a bit), as \[ \begin{align} f_R(h) &\overset{\star}{=} f_\Delta\big(T^{-1}h\big)\, \underbrace{\big|\det T^{-1}h\big|}_{= |1 / \det T| = 1}\\[5px] &= \frac{I\big\{ h_1 \in H_1,\, \forall i \geq 2 : h_{i-1} - h_i \in Q \big\}}{|H_1||Q|} \,. \end{align} \] Notice that the above indicator defines a set \(B \subset \mathbb{R}^n\) and since all PDF's must integrate to \(1\), we further obtain \[ 1 = \int f_R \,d\lambda^n = \frac{1}{|H_1|\,|Q|} \int_B d\lambda^n = \frac{|B|}{|H_1|\,|Q|} \] showing that \(f_R(h) = I\{h \in B\}\, |B|^{-1}\) and consequently \(R \sim \mathcal{U}(B)\). This allows us to nicely approximate the desired probability. Consider \(\phi\) to be the ratio of \(lA \cap B\) in \(B\). It then holds \[ P(R \in lA) \overset{R \sim \mathcal{U}(B)}{=} \frac{|lA \cap B|}{|B|} = \frac{\phi\,|B|}{|B|} = \phi \,.\] Now consider \(Y^{(j)} \overset{iid}{\sim} \mathcal{U}(B)\) yielding \(I\{Y^{(j)} \in lA\} \overset{iid}{\sim} \mathcal{Bin}(1,\phi)\) by definition of \(\phi\). Hence we can construct the following estimator and apply the law of large numbers to get the asymptotic \[ \hat{\phi}_\nu := \frac{1}{\nu} \sum_{j \leq \nu} I\{Y^{(j)} \in lA\} \ \overset{\nu \to \infty}{\longrightarrow}\ P(R \in lA) \,. \] Finally, notice that \(Y^{(j)} = T^{-1}\Delta^{(j)}\) allowing us to easily generate \(Y^{(j)} \sim \mathcal{U}(B)\). And that's it! The most challenging part for me was realizing that the distribution of \(R\) could be obtained from the much simpler \(\Delta\). Once I knew that \(R \sim \mathcal{U}(B)\) I quickly had the discussed approximation down. To implement this in code, we begin by defining a function to sample \(\Delta^{(j)}\) as well as one to transform them via \(T^{-1}\).
JS
// corresponds to Δ = (R_1,Δ_2,...,Δ_n)
const sample = () => {
// corresponds to R_1 ~ U(H_1)
const sample = [UTIL.randFl(init.min, init.max)];
// corresponds to Δ_i ~ U(Q)
for (let i = 1; i < data.length; i++)
sample[i] = UTIL.randFl(delta.min, delta.max);
return sample;
};
// corresponds to T^(-1)Δ ~ U(B)
const transform = (sample) => {
// corresponds to (T^(-1)h)_1 = h_1
let result = [sample[0]];
// corresponds to (T^(-1)h)_i = h_(i-1) - h_i
for (let i = 1; i < sample.length; i++)
result.push(result[i - 1] - sample[i]);
return result;
};
Sampling \(\Delta^{(j)}\) by pulling components from \(H_1\) and \(Q\)
and transforming a \(\Delta^{(j)}\) sample into \(Y^{(j)} \sim \mathcal{U}(B)\) via \(T^{-1}\).
and transforming a \(\Delta^{(j)}\) sample into \(Y^{(j)} \sim \mathcal{U}(B)\) via \(T^{-1}\).
Next, we need to implement \(I\{Y^{(j)} \in lA\}\) i.e. check if \(Y^{(j)}_i \in lA_i\) for all \(i\) where \(l\{k_i\}\) is as before and \(lA_i = H_i\) is the smallest interval such that \(R_i \in H_i\) almost surely.
JS
// corresponds to lA_i
const interval = (i) => !data[i]
// unobserved datapoint return H_i
? [init.min - i * delta.max, init.max - i * delta.min]
// observed datapoint return l{k_i}
: [(data[i] - 1) / base, data[i] / base];
// corresponds to I{Y ∈ lA}
const valid = (rates) => rates.every((rate, i) => {
const [low, high] = interval(i);
return rate >= low && rate <= high;
});
Implementation of indicator \(I\{Y^{(j)} \in lA\}\) by checking each component.
Putting everything together, the
JS
DEC.evaluateMC = function(data, steps = 50_000) {
const { base, init, delta } = this;
// implemented as stated above
const sample, transform, interval, valid;
// if no data observed, return prob = 1
if (data.every((x) => !x))
return { hits: steps, ratio: 1 };
// approximate phi by LLN
let hits = 0, n = steps;
while (n-- > 0) {
const sequence = transform(sample());
if (valid(sequence)) hits += 1;
}
return { hits, ratio: hits / steps };
}
Evaluation function of "Decreasing" phase utilizing Monte Carlo Estimation.
DEC Phase (RC)
While the MC approach provides an elegant asymptotic solution in theory, it
unfortunately suffers from several practical limitations. For starters, it is
inherently non-deterministic, meaning that evaluating
\(P(X\,|\,\texttt{DEC}_{\texttt{MC}})\) for the same data \(X\) twice may yield
slightly different results. Of course, this can be mitigated to some extend by running
a longer estimation (i.e. checking more \(I\{Y^{(j)} \in lA\}\)), however even with
multithreading
 remains little more than a band-aid fix.
remains little more than a band-aid fix.
More importantly, the method appears to degenerate quite aggressively with higher dimensionality (i.e. longer phases to check) and rare boundary cases (i.e. sequences that lie near the edge of possibility). I suspect that probing for \(lA\) simply using \(Y^{(j)} \sim \mathcal{U}(B)\ iid\) may not be sufficient in practice, even thought the theory clearly doesn't care. A possible fix would therefore need to implement a more sophisticated probing strategy, such as adaptive grids or similar techniques.
We will now cover the RC approach, which I discovered online and whose theoretical foundation is given by the Chapman-Kolmogorov equation. However, I believe it is more approachable to develop the tools we actually need ourselves. To that end, let \(X_1,\ldots,X_n\) be independent and satisfy \[ X_i \sim \mu_i, \;\; Y_i = Y_{i-1} + X_i, \;\; Y_1 = X_1 \,. \] We are interested in the distribution of the random walk \(Y = (Y_1,\ldots,Y_n)\). The key idea is based on the fact that \(Y_i = X_1 + \cdots + X_i\) is a sum of independent random variables. Therefore, its distribution can be obtained by convolving the distributions \(\mu_1,\ldots,\mu_i\).
Theorem. For a function \(f\), sets \(A_i\), and distributions \(\mu_i\) as above, define \(M_i f := f \cdot I_{A_i}\) and \(C_i f := f * \check{\mu}_i\). Then the recursion \(u_{i-1} = M_{i-1} C_i\, u_i\) with \(u_n = I_{A_n}\) yields \[ P(\forall i: Y_i \in A_i) = \int u_1(x) \,\mu_1(dx) \,. \]
Before proving the theorem, it is helpful to understand the intuition behind it. The operator \(M_{i-1}\) encodes the constraint \(Y_{i-1} \in A_{i-1}\) into \(u_i\), while the operator \(C_{i}\) encodes the (reflected) distribution \(\check{\mu}_i\) of the increment \(X_i\). As the recursion concludes, all constraints and all distributions, except \(\mu_1\) have been encoded into \(u_1\). Therefore, the desired probability can be obtained by simply integrating \(u_1\) against \(\mu_1\).
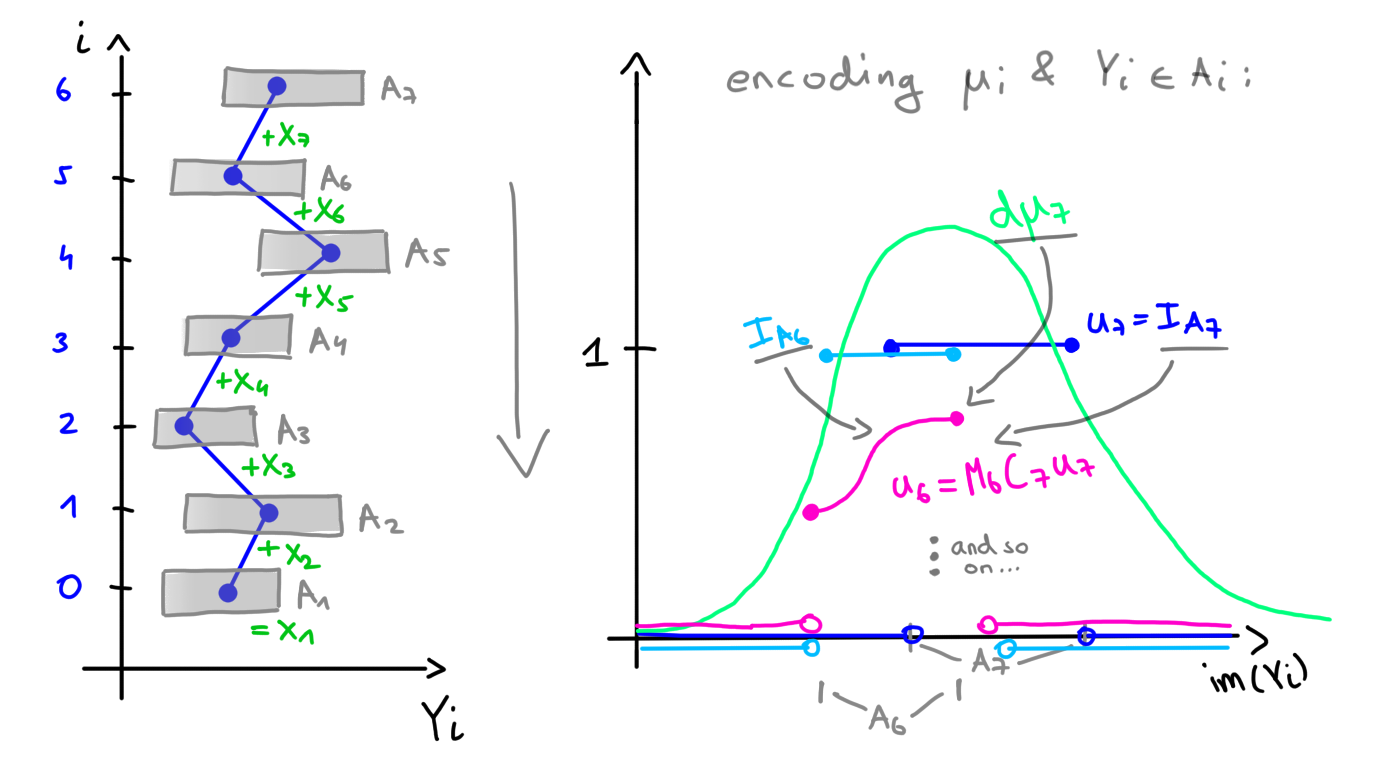
Encoding \(\mu_i\) and \(Y_i \in A_i\) into \(u_1\) (placeholder).
Proof. TODO: write the proof
Work in Progress. Will be finished soon™.